
SQL

本文以mysql为例…
SQL通用语法
- SQL语句可以单行或多行,分号结尾
- MySQL数据库的SQL语句不区分大小写,关键字建议大写
- 注释如下(注意
--后面有空格)
单行注释: -- 注释内容 或 #注释内容(MySQL特有)
多行注释: /* 注释 */SQL分类
- DDL(Data Definition Language)数据定义语言,用来定义数据库对象:数据库,表,列等
- DML(Data Manipulation Language)数据操作语言,用来对数据库中表的数据进行增删改
- DQL(Data Query Language)数据查询语言,用来查询数据库中表的记录(数据)
- DCL(Data Control Language)数据控制语言,用来定义数据库的访问权限和安全级别,及创建用户
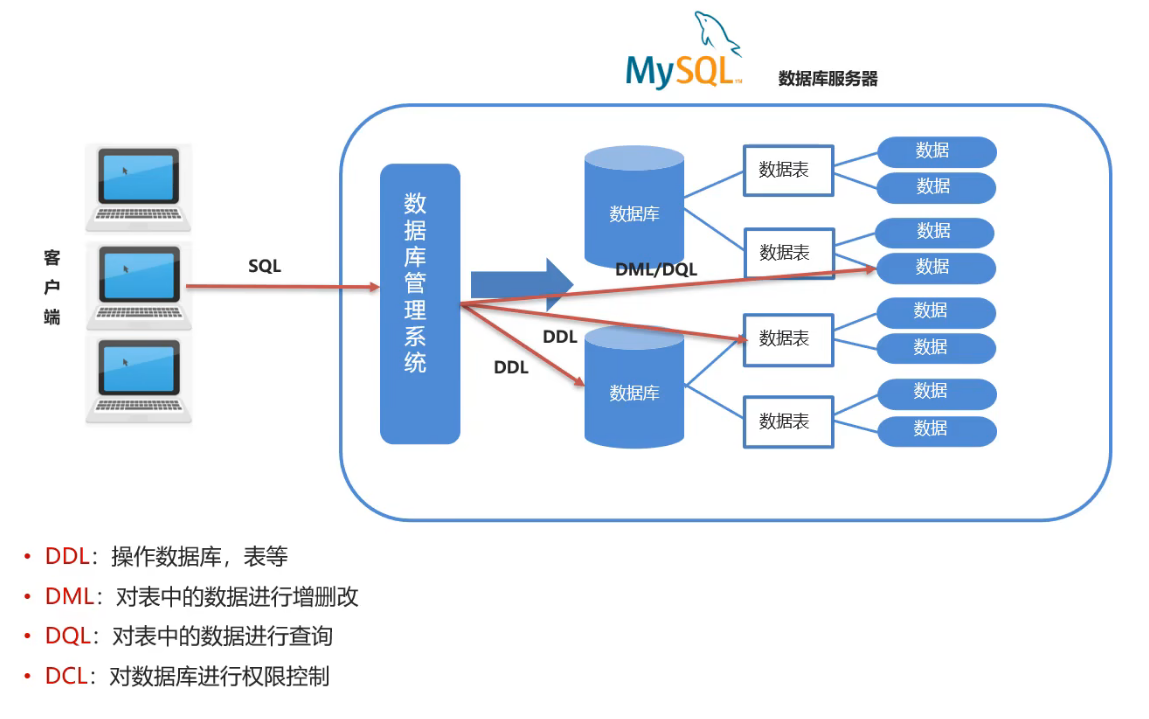
DDL-操作数据库、表
操作数据库
查询
show databases;创建数据库
create database 数据库名称; create database if not exists 数据库名称; -- 判断否存在删除数据库
drop database 数据库名称; drop database if exists 数据库名称; -- 判断是否存在使用数据库
select database(); use 数据库名称;
操作数据表
查询当前数据库下所有表名称
show tables;查询表结构
desc 表名称;创建表(注意最后一行末尾,不能加逗号)
create table 表名 ( 字段名1 数据类型1, 字段名2 数据类型2, ... 字段名n 数据类型n );删除表
drop table 表名; drop table if exists 表名; -- 判断是否存在修改表名
alter table 表名 rename to 新的表名;添加一列
alter table 表名 add 列名 数据类型;修改数据类型
alter table 表名 modify 列名 新数据类型;修改列名和数据类型
alter table 表名 change 列名 新列名 新数据类型;删除列
alter table 表名 drop 列名;
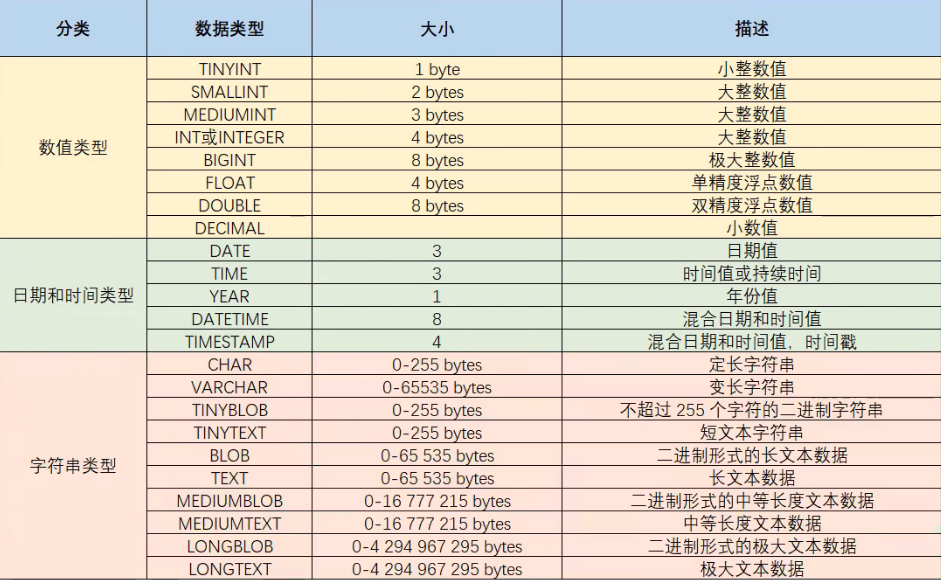
数据类型
MySQL数据类型可以分为以下三类:
- 数值
- 日期
- 字符串
PS:
score double(总长度,小数点后保留的位数)
score double(5,2) -- 0~100 2(5为3+2)name char(10) -- 定长
name varchar(10) -- 变长
-- 如果将“张三”字符存入两种类型,char占用10个字符空间,varchar占用2个字符空间
-- char存储的性能高 浪费空间 varchar存储性能低 节约空间DML-增删改数据
给指定列添加数据
insert into 表名(列名1,列名2,...) values(值1,值2,...); insert into stu(id,name) values(1,'张三');给全部列添加数据
insert into 表名 values(值1,值2,...);批量添加数据
insert into 表名(列名1,列名2,...) values(值1,值2,...),(值1,值2,...),(值1,值2,...)...; insert into 表名 values(值1,值2,...),(值1,值2,...),(值1,值2,...)...;修改表数据
update 表名 set 列名1=值1,列名2=值2,... where 条件; -- 修改语句中如果不加where条件,则将所有数据都修改 update stu set birthday = '1999-12-12', score = 99.99 where name = '张三'; -- 案例删除数据
delete from 表名 where 条件; -- 删除语句中如果不加where条件,则将所有数据删除
DQL-查询表的记录、数据
查询语法
select
字段列表
from
表名列表
where
条件列表
group by
分组字段
having
分组后条件
order by
排序字段
limit
分页限定基础查询
查询多个字段
select 字段列表 from 表名; select * from 表名; -- 查询所有列的数据去除重复记录
select distinct 字段列表 from 表名;起别名
as -- as也能省略 select name as 姓名,math 数学成绩,english 英语成绩 from stu; -- 案例 select name as 姓名,math as 数学成绩,english as 英语成绩 from stu; -- 案例
条件查询
条件查询语法
select 字段列表 from 表名 where 条件列表;条件
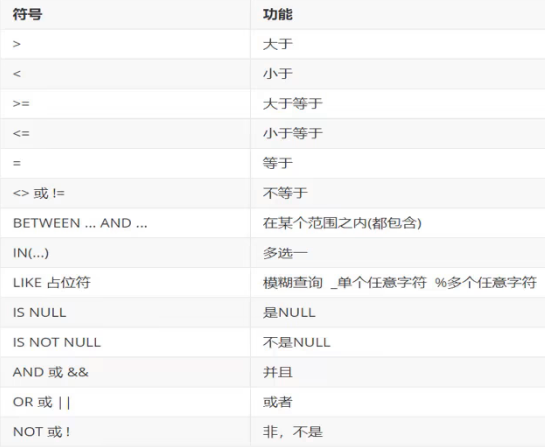
注意:
- 与
Java不同的是等号是=而不是== Null不能使用=而应该使用is或is not&&和and通用,||与or通用like模糊查询中下划线_代表单个任意字符,%代表多个任意字符(可以是0个)
排序查找
排序查找语法
select 字段列表 from 表名 order by 排序字段名1 排序方式1,排序字段名2 排序方式2;排序方式:
ASC:升序排列(默认值)
DESC:降序排列
如果有多个排序条件,当前边的条件值一样时,才会根据第二条件进行排序
聚合函数
概念:将一列数据作为一个整体,进行纵向计算
分类:
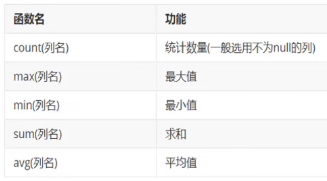
语法:
select 聚合函数名(列名) from 表;注意:
null值不参与所有聚合函数运算count一般使用*,新版mysql中会自动选择速度最快的一列进行计算
分组查询
分组查询语法
select 字段列表 from 表名 where 分组前条件限定 group by 分组字段名 having 分组后条件过滤;注意:分组之后查询的字段为聚合函数和分组字段,查询其他字段无任何意义(比如求男女平均成绩还去查姓名就无意义)
where和having的区别:
- 执行的时机不一样:
where是分组前,而having是分组之后对结果进行过滤 - 可判断的条件不一样:
where不能对聚合函数进行判断,having可以 - 执行顺序:
where>聚合函数>having
分页查询
分页查询语法
select 字段列表 from 表名 limit 起始索引,查询条目数;注意:
- 起始索引=(当前页面-1)*每页显示的条数
MySQL使用limit,Oracle使用rownumber,SQL Server使用top
约束
约束的分类
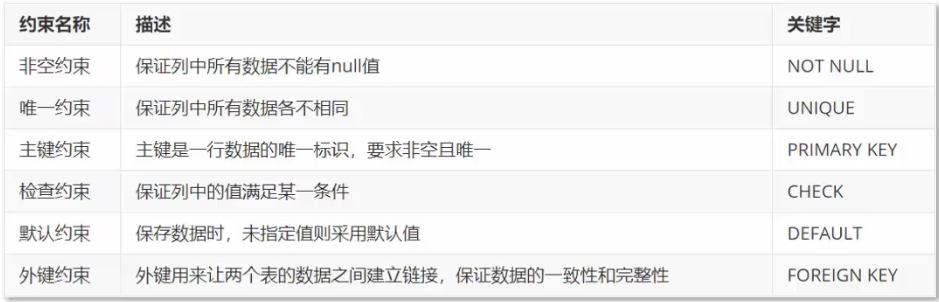
注意:
MySQL在8.0.16版本以前不支持检查约束- Null也是个值,不算空
primary key auto_increment主键且自增长:数字类型
基本语法
创建表时添加:
create table emp(
id int primary key auto_increment, -- 主键且自增长
ename varchar(50) not null unique, -- 非空且唯一
joindate date not null, -- 非空
salary double(7,2) not null, -- 非空
bonus double(7,2) default 0 -- 默认0
);建完表后添加
alter table 表名 modify 字段名 数据类型 约束类型;删除约束
alter table 表名 modify 字段名 数据类型;外键约束
从表—–>主表(例:员工—–>部门),并且要先创建主表
语法:
创建表时添加外键约束
create table 表名( 列名 数据类型, ... constraint 外键名称 foreign key(外键列名) reference 主表(主表列名) );建完表后添加外键约束
alter table 表名 add constraint 外键名称 foreign key(外键列名) reference 主表(主表列名)删除约束
alter table 表名 drop foreign key 外键名称;
多表查询
select * from emp,dept; -- 案例若emp有4条数据,dept有6条数据则会查询到24条数据
笛卡尔积:有A,B两个集合,取A,B所有的组合情况
添加条件可以消除无效数据
select * from emp,dept where emp.dep_id = dept.did; -- 案例(内连接)连接查询
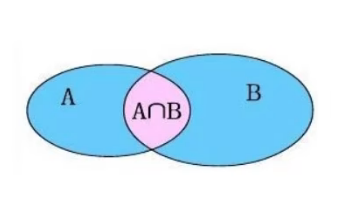
内连接:相当于查询A B交集数据

- 查询语法:
select 字段列表 from 表1,表2... where 条件; -- 隐式内连接 -- 可以在表后面给表起别名:from 表1 别名1,表2 别名2 select 字段列表 from 表1 inner join 表2 on 条件; -- 显示内连接(inner可以省略)外连接:
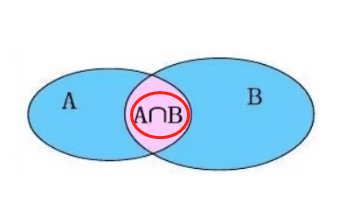
左外连接:相当于查询A表所有数据和交集部分数据
- 查询语法:
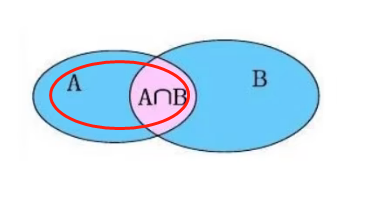
select 字段列表 from 表1 left outer join 表2 on 条件; -- outer可以省略右外连接:相当于查询B表所有数据和交集部分数据
- 查询语法:
select 字段列表 from 表1 right outer join 表2 on 条件; -- outer可以省略
子查询
查询中嵌套查询
案例:
-- 查询工资高于猪八戒的员工信息
select salary from emp where name = '猪八戒'; -- 得3600
select * from emp where salary > 3600; -- 查询大于3600通过子查询可以合并为:
select * from emp where salary > (select salary from emp where name = '猪八戒');查询语法
单行单列:作为条件值,使用
=!=><等进行条件判断select 字段列表 from 表 where 字段名 = (子查询);多行单列:作为条件值,使用in等关键字进行条件判断
select 字段列表 from 表 where 字段名 in (子查询);多行多列:作为虚拟表
select 字段列表 from (子查询) where 条件;
事务
要么同时成功,要么同时失败
语法
开启事务(两种皆可)
START TRANSACTION; BEGIN;提交事务
commit;回滚事务
rollback;
自动提交
SELECT @@autocommit;
set @@autocommit = 0; -- 1自动提交,0手动提交四大特征(ACID)
原子性(Atomicity):事务是不可分割的最小操作单位,要么同时成功,要么同时失败
一致性(Consistency) :事务完成时,必须使所有的数据都保持一致状态
隔离性(Isolation):多个事务之间,操作的可见性
持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的
触发器
触发器是指在增删改之前或之后触发并执行触发器中定义的SQL语句集合
使用别名OLD和NEW来引用触发器中发生变化的记录内容

语法
创建
CREATE TRIGGER trigger_name
BEFORE/AFTER INSERT/UPDATE/DELETE
ON tbl_name FOR EACH ROW --行级触发器
BEGIN
trigger_stmt;
END;查看
SHOW TRIGGERS;删除
DROP TRIGGER [schema_name.]trigger_name; --如果没有指定schema_name,默认为当前数据库











